There is a reference copy of the paper also available in the on-line conference Proceedings as http://www.igd.fhg.de/www/www95/proceedings/papers/87/HRM.html. This reference copy can also be found in the Author Index under "Donnelley" or in the Session List in the second session on Enhancements to the Lower Level WWW Protocols. Hardcopy of the paper is available in the journal Computer Networks and ISDN Systems, Volume 27, issue 6.
A note on the references - to jump to the references section of the paper to look at a citation, click on the numeric reference entry in bracketed references. E.g. in "[BER92-1]" click on the 1. If the alphanumeric reference is a URL, e.g. "BER92" in this case, then clicking on it will take you to the "local" copy (either in Livermore or in Stuttgart depending on where you are accessing this page) of the reference itself - beware.
Postscript versions of this paper are available in both U.S. letter and in European A4 formats.
If you are somehow looking at a hardcopy version of this paper and wish to view it on the WWW, you can find it at the URL:
http://www.webstart.com/jed/papers/HRM/HRM.html
This HTML version was updated to correct various links, August 10, 1995.
This HTML version was again updated to correct various links, August 10, 1998.
"James E (Jed) Donnelley"
<jed@llnl.gov>
http://www.webstart.com/jed/jed.html
Hopwise Reliable Multicast (HRM) is proposed to simplify reliable multicast of non real time bulk data between LANs. HRM uses TCP for reliability and flow control on a hop by hop basis throughout a multicast distribution tree created by today's Internet MBone.
In the present paper we focus on access to non real time "mass" media publications. These include magazines, their briefer "zine" cousins, newspapers, journals, advertising catalogs, etc. The discussion is also applicable to distribution of many types of relatively static bulk data. Excluded from this discussion are real time media such as radio, television, telephone, etc. and dynamic WWW pages.
Magazines, newspapers, advertising catalogues, and other such media are beginning to appear on the WWW at an amazing rate. The author is currently supporting a set of WWW pages (the Computer and Communications set at: http://www.cmpcmm.com/cc/) that provide "One-stop shopping" for information about computers and communication. In this set there is a media page which at the time this paper was written contained URLs to about 50 magazines and newspapers relating to computers and communications.
Many of the publications beginning to appear on the Web should be considered experimental. Even in their current form, however, they are quite useful for those of us that use the Internet as an important source of information. The available searching facilities alone in some cases make Web access to such information considerably more useful than access to the equivalent printed page. To this advantage can be added the ability to reference material outside the article with a click, the ability to copy and paste relevant material, the ability to access such pages anywhere the Internet can be accessed, and others. The unique capabilities of Web access are beginning to incline some of us to read WWW media pages in preference to reading hardcopy, despite some continuing advantages to hardcopy such as portability, mass quick scanning, markability, etc.
As Internet users we must be concerned by the prospect of millions of readers beginning to access media material over the Web. With the current mechanisms for transporting this material, repeated transport of just the graphical page headings alone would constitute a significant additional load for the Internet.
To ease the load on Internet produced by WWW media requests this paper presents two suggestions:
1. The Distribution Point Model - a model where media is copied to distribution points on Local Area Networks and then accessed locally, and
2. Hopwise Reliable Multicast - a multicast mechanism that builds on the current Internet MBone and allows efficient transmission of bulk data from one point to many others.
Before considering the Distribution Point Model in more detail, it is appropriate to consider some alternatives.
1. Caching reduces the WAN load for multiple accesses from the same site, but still requires as many WAN accesses as there are requesting cache sites.
2. The first access to a page and any access that results in a cache miss subjects readers to the vagaries of WAN access (higher latencies, service disruptions, etc.).
3. There is currently no effective cache notification for WWW page changes. This means that anyone using a caching service may get an old page from the caching service when a new page is available from the source server. This discourages use of caching services.
If the distributed file system approach does prove successful (whether with today's systems or with further DFS development) there is still a difficult optimization problem that may benefit from some of the considerations in this paper.
When a file is remotely requested for the first time, a DFS must decide how to get it to the requesting site. One approach is to move it directly through the network from the source to a cache at the requesting site. This approach, while it may be appropriate in some instances, suffers from problems #1 and #2 discussed in the caching section above.
Another approach a DFS might take is to "stage" a requested file through multiple caches between the source and the requesting site. If caching sites are as dense as nodes in a multicast distribution tree, this approach reduces WAN load exactly like multicast distribution (e.g. with HRM). A difference is that with such a distributed caching approach copies of the file must be supported at the intermediate caching nodes for an extended period of time.
To eliminate the need for extended caching at intermediate nodes while still retaining the advantages of reduced WAN load due to multicast distribution, a DFS could use a reliable multicast transport mechanism (whether HRM or some other) to transport files to remote caches for local access. Doing such transport to likely access sites when a file is first created would be equivalent to the Distribution Point Model over multicast as proposed in this paper. Waiting until a file is first accessed and then using multicast distribution to a set of known likely access sites would have the advantage of not transporting any data until it is requested, but would still suffer from problem #2 above (slower first access).
Distributed file systems face a difficult challenge in providing configuration parameters that efficiently deal with the many common patterns of file access. A suggestion from this paper is that they consider multicast distribution to likely access points.
Mechanisms are under development to securely identify who is accessing a Web page (e.g. PGP [PGP94-3] integration into WWW software [NET94-4], using the Secure Socket Layer [HIC94-5] under Web software, etc.). We assume that such mechanisms will exist and can be used by the servers at the distribution points to identify users and restrict access. These identification mechanisms can be used directly with the current magazines on the Web serviced by a single server. In this paper we only consider the additional complications introduced by utilizing multiple distribution points as suggested by the Distribution Point Model.
With distributed access the publisher and the distribution point servers must together manage media access. This requires a distributed database for which a caching or distributed file system would be appropriate. There is little data transfer required so performance is not a concern. A publisher could simply send updates to the distribution points periodically.
As an aside, it seems reasonable to the author to allow some number of accesses to a magazine for free before beginning to charge for it. This sort of "lost leader" is in many ways analogous to the "first issue is free" policy that is often followed today by hardcopy magazines. This would suggest that Web servers should have somewhat more sophisticated access control policies that can be used to count accesses by users and notify them as access control restrictions are about to be (and ultimately are) imposed.
In the remainder of this paper we assume that we are going to use the Distribution Point Model to improve performance and reduce WAN load for WWW page access and focus on the technical problem of getting the bulk data to the distribution points.
The Internet MBone currently sends UDP datagrams over this multicast structure. The IP multicast structure does not concern itself with lost packets. Typically packet losses are due to congestion on the network rather than errors on the lines. Dealing with any such losses are left to higher level protocols (e.g. the reliable multicast transport protocols). For real time communication such as audio or video there is not too much one can do about lost packets. If lost packets are retransmitted, they will likely arrive too late to be useful in playout of real time media transmissions.
With real time data this specific form of congestion is not quite so readily generated. If the sender is to be received by everyone listening, it must not send data so quickly that such congestion is created. However, having selected a transmission rate (e.g. media quality, frame rate, compression, or other parameters) the sender cannot send data any faster than the data is generated.
In the bulk data case the sender would prefer to send the data as quickly as possible. In general the sender has no idea how bad the available bandwidth is on the worse case link that will ultimately receive the data. Of course senders can get reports from receivers (e.g. "Session" Packets [JAC94-16]), but such reporting creates a rather complex and long distance feedback loop with possibly long latencies. Lost packets must be retransmitted to the whole multicast group, thereby requiring bandwidth over many links for a problem that may well be relatively isolated. An additional problem is the "Ack Implosion" problem (many acks from all the receivers arriving at the sender [JAC94-16]). While programs like "wb," the currently most popular "white board" tool on the MBone, and others can overcome these problems to various degrees and succeed in multicasting reliably, the focus of this paper is on an alternative approach.
In more detail, the multicast routing mechanisms of mrouted are used as they operate now. However, to send a multicast "packet" (which we refer to here as a "block"), a TCP connection is opened to each of the links that are to receive the block and the data is transmitted at the best possible rate. Since very large blocks of data are being transmitted, it is important that each node begin to transmit the received data onward to the next appropriate links (tunnels) in the distribution tree before the data is completely received. This "cut through" approach is important both to allow buffer sizes in the nodes to be bounded and to cut down on the latency of the transmission.
With HRM the buffers in the intermediate nodes can be configured to optimize local performance. If the buffers are too small, small TCP transmissions will result in inefficient use of network resources. Beyond the point where buffers are adequate for smooth hopwise TCP transmission, larger buffers effectively allow more buffering of data in the network, thereby offloading the source more quickly and possibly allowing some nodes to receive completed blocks more quickly. Such larger buffers have no effect on the time to complete a multicast, i.e. the time until the last node receives the complete block.
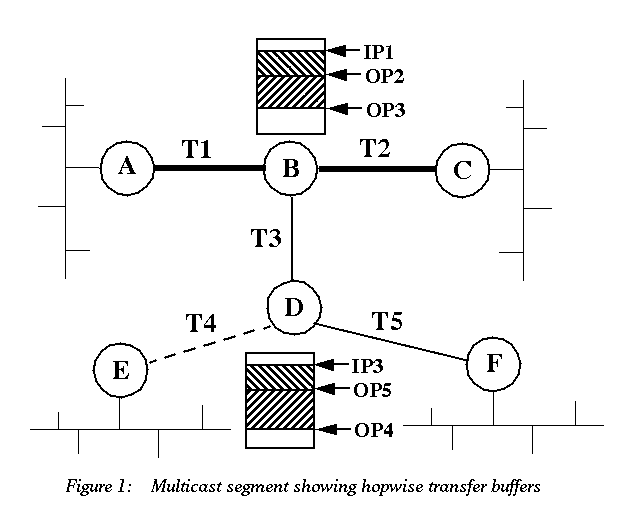
An example of the buffering at intermediate nodes in a HRM transfer is illustrated in figure 1. The buffers are circular with an input pointer (IP<i> in the figure) and as many output pointers (OP<i>) as there are output links in the multicast distribution tree (bounded above by the fanout of the multicast node).
In the example shown, node B has a relatively fast output link T2 and a slower (or currently more congested) output link T3. In this case OP2 would tend to track the IP1, while OP3 would tend to lag behind. When IP1 wraps around and catches OP3, the buffer is full and the TCP window to node A is closed.
Naturally with a scheme of this sort it is important to only send data in blocks large enough for reasonable performance. Until a connection is closed a node always knows to expect more data and so need only transmit data out when its buffers are "reasonably" full.
If it is determined that one or more sites did not receive a distribution, it would be necessary to retransmit the whole block, either by unicast if there were very few such sites or again by HRM if there were many such sites. In either case communication with the remaining sites must again be established before initiating further distribution.
It would be unfortunate if a technology like HRM caused the life of the current "virtual" Internet MBone to be extended beyond the time when routed IP multicasting is supported. There are some very awkward administrative features of the current MBone, most notably its requirement to "track" the topology of the actual Internet to avoid wasteful retranmissions of data. Perhaps one of the reliable transport protocols currently under development will work out well and come to be widely accepted. In this case such a protocol could be used across a routed Internet multicast facility to provide distribution of WWW media.
A limitation of HRM is that it is not appropriately used over LAN links with hardware supported multicast. In this case use of HRM would unnecessarily replicate data transmission over the LAN. This limitation is not significant for the Distribution Point Model where distribution is only needed to a single LAN site. In the larger context of multicast transport, the approach of HRM could be combined with a reliable "single hop" multicast transport over links where hardware multicasting is supported.
Despite it's limitations, the author finds the mechanisms of the hop by hop approach to reliable multicast compellingly simple. Both congestion control and error control are significantly simplified by this approach. Perhaps it will be worthwhile to experiment with the HRM approach in parallel with the efforts to develop reliable transport protocols on top of routed multicast datagram services.
There are several groups currently investigating using reliable multicast transport for bulk data distribution. It is suggested that the current MBone with the extension described here (HRM) may be better suited to dealing with the distribution of such non real time bulk data, at least in the short term.
Reliable multicast technology is suggested to further reduce the network load induced by media distribution. Hopwise Reliable Multicast is suggested as an approach that can extend the current Internet MBone to simplify multicast transport in the case of non real time bulk data transport.